Personal AI Tutors
All code for this project is available on GitHub.
Bloom’s 2 Sigma Effect
Bloom’s 2 Sigma Effect refers to a phenomenon where students who receive one-on-one tutoring from a human tutor using mastery learning outperform their peers who receive traditional classroom instruction by two standard deviations. Mastery learning is an approach that focuses on ensuring that students fully understand and master a concept or skill before progressing to the next topic. This equates to a significant boost in educational attainment. However, providing low-cost, accessible and personalised tutoring is practically unscalable.
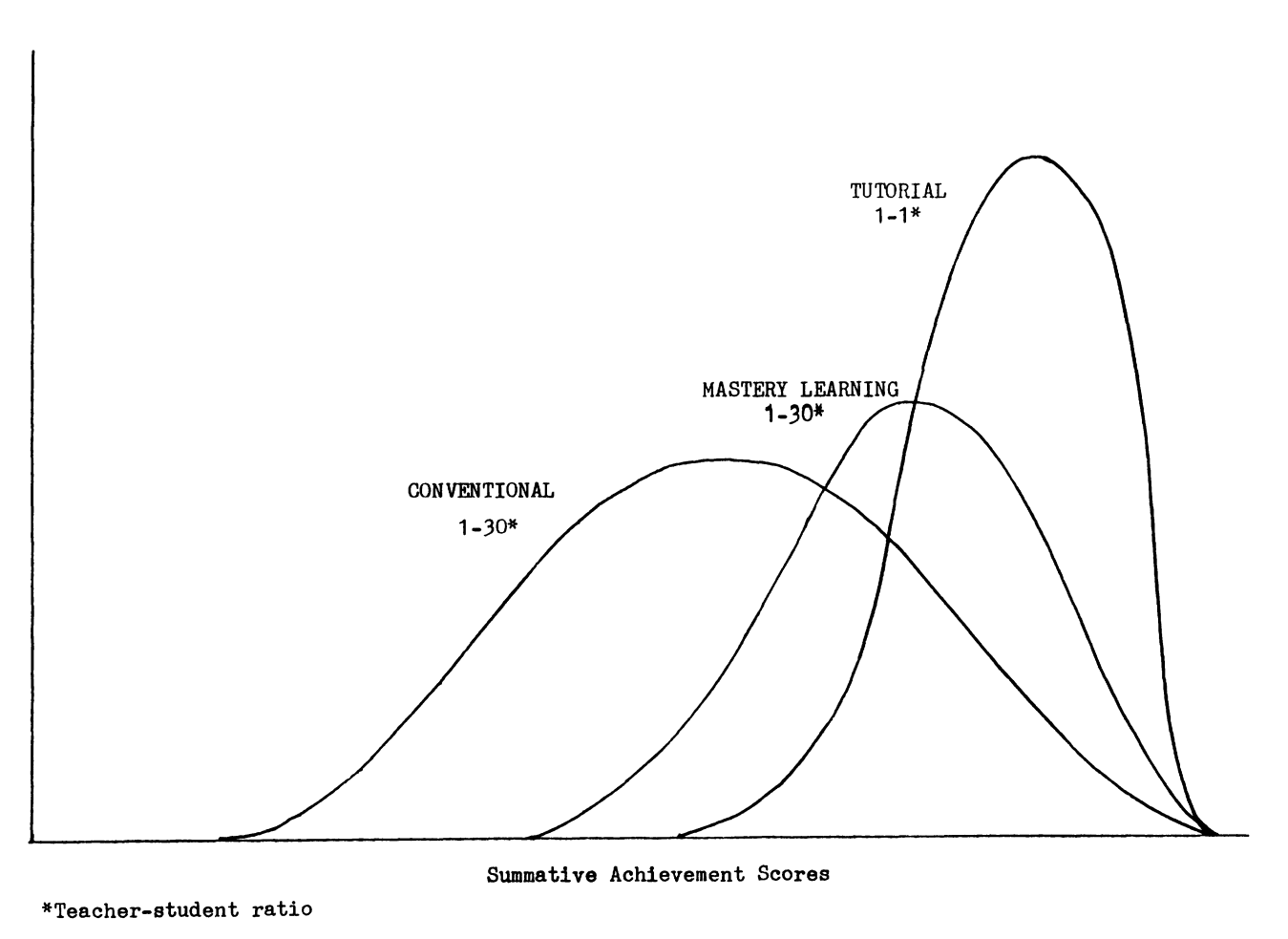
Top universities such as Oxford and Cambridge employ small-group tutorial systems as a part of their academic approach, but these sessions are often limited to an hour every week or two. While these tutorials offer an intimate learning environment and foster in-depth discussions, they can be costly and less accessible: such tutorial systems are typically confined within the walls of these prestigious institutions, making them available to a select few. Consequently, the benefits of these tutorial systems are not as widely enjoyed as they could be.
Bloom’s assertion that one-to-one tutoring is “too costly for most societies to bear on a large scale” was a reasonable stance at the time he made it, in 1984. However, with the advent of the LLM revolution, there is a high probability he will be proved wrong. Personal AI Tutors, fueled by the advancements in LLM’s, have the potential to provide tailored education to students on a massive scale, making personalized education accessible and affordable for all.
CodeTutorGPT: An experiment in AI Tutoring
I was wanting to dive into learning C, after recommendations from various programmers. Simultaneously, I was immersed in recent projects utilizing LLMs to create autonomous agents. This lead me to my great procastionation idea: why not postpone diving into C programming by first developing an AI tutor agent to guide me through the learning process?
Here is the basic architecture I came up with:
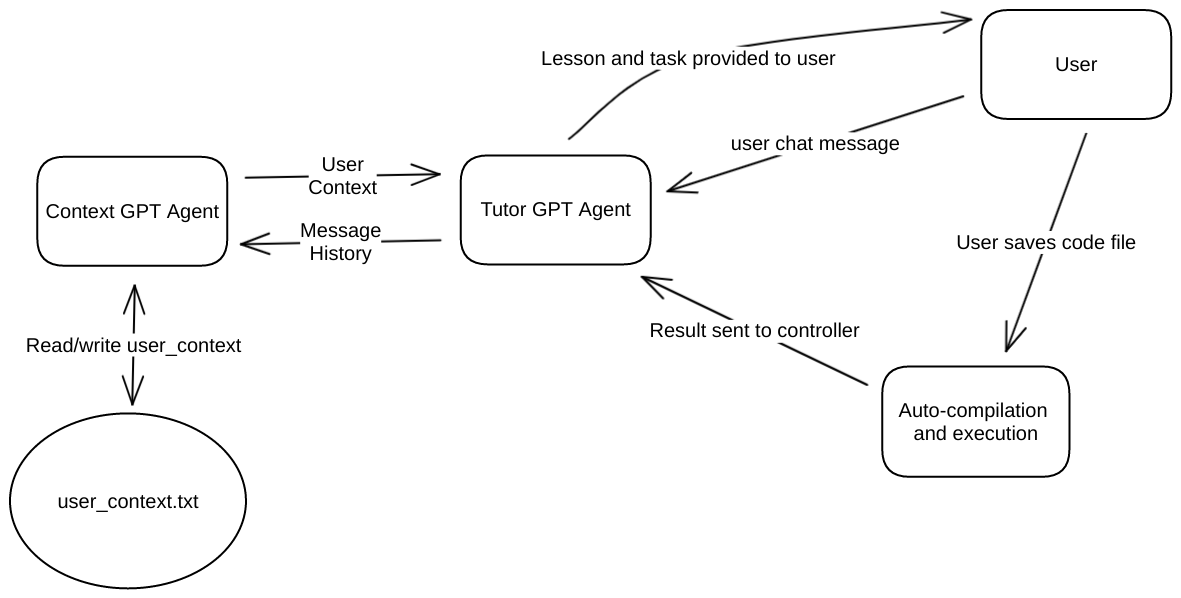
The basic cycle is as follows:
- The student tells the AI tutor what they want to learn about via a chat interface.
- The AI tutor is then also provided a user context, via the context agent, which documents the student’s current level of the student’s understanding of the language.
- The tutor creates a personalised lesson on the topic provided this context, followed by a programming excercise to test the student’s understanding.
- When the student saves the ‘lesson.c’, the code is automatically compiled and executed. The result of the execution, whether it be an error or program output, is provided to the tutor along with the code.
- The tutor then provides feedback on the student’s code, and may even provide follow on topics and excercises for the student to complete.
Let’s take a look at an example of how this might work in practice:
-
I tell the AI tutor they want to learn about pointers.

-
This message is forwarded to the context agent, which documents my current level of understanding in conjuction with the previous context. In this case, I had no previous context. Here is what the context agent documented:
Based on the student's recent message, it appears that they are interested in learning about pointers in programming. However, without further information, it is difficult to determine the student's current understanding of the topic. It is recommended that the tutor assess the student's knowledge of pointers and tailor their instruction accordingly. -
This user message, along with the context, is then forwarded to the tutor, which creates a personalised lesson on pointers, followed by a programming excercise to test the student’s understanding. Here is the lesson the tutor created:
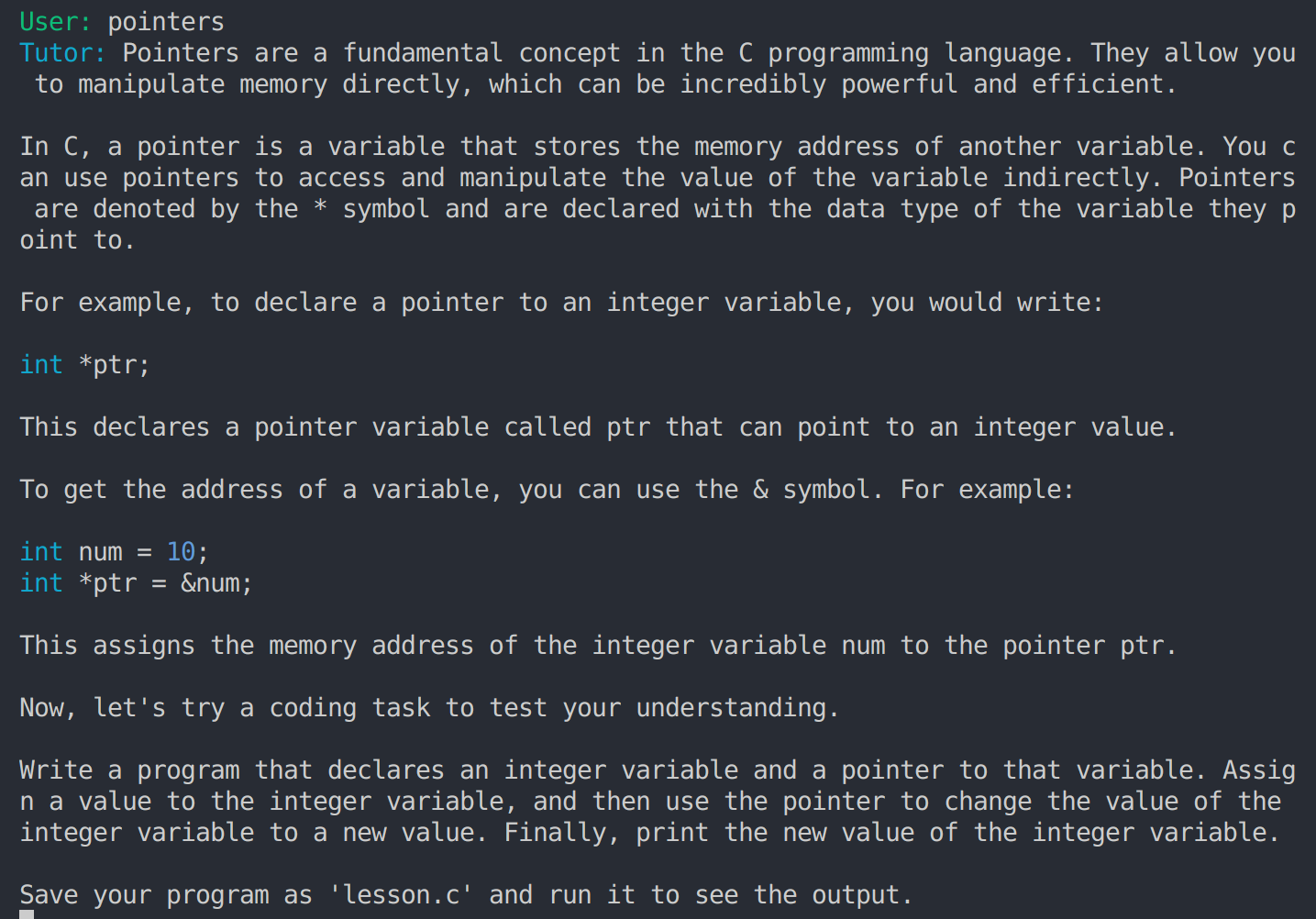
-
Let’s initially create a program with an error to see how the tutor responds. Here is the code I wrote:
#include <stdio.h> int main() { int x = 5; int *ptr = &x; ptr = 10; printf("%d\n", x); return 0; }Note at
ptr = 10;I have assigned a value to the pointer instead of using it to change the value of the integer variable. -
The program auto compiles and executes, producing an output of
5. This is then first provided to the context agent. The updated context is as follows:Based on the student's recent message, it appears that they are interested in learning about pointers in programming. The student has a basic understanding of pointers in C programming language. They know that pointers are variables that store the memory address of another variable and can be used to access and manipulate the value of the variable indirectly. The student also knows how to declare a pointer variable and get the address of a variable using the & symbol. However, the student needs improvement in using pointers to change the value of a variable. In the coding task provided, the student assigned a value to the pointer instead of using it to change the value of the integer variable. The tutor should provide more practice exercises to help the student improve their understanding of using pointers to manipulate variable values. -
Finally, the tutor responds with feedback to the student:
 The tutor successfully identified the error in the student’s code, and explained what to do!
The tutor successfully identified the error in the student’s code, and explained what to do!
In conclusion, this system works really well, and I have been personally using it to learn C, along with the famous C Programming Language book. However, I must acknowledge some shortcomings.
Shortcomings and Potential Solutions
GPT-3+ demonstrates a good understanding of common subjects, but it is crucial to be aware of potential hallucinations. For niche topics, or new topics that emerged after its training data cut-off date, it may confidently provide false information.
One solution is to create embeddings from factual data sources, such as documentation and books, and then use vector search to retreive accurate information that can be fed into a LLM. OpenAI offers an example of how this can be achieved. While I did actually implement this into CodeTutorGPT, I didn’t find it to offer significant improvement for learning C.
Another limitation is the simplicity of my context agent. The agent overwrites the entire previous context at each step, so if it does not include context from previous steps, that information will be lost. Moreover, it is relatively resource/token-intensive, as it reads and writes the entire context file each time.
One potential solution could involve using an embedding vector space to store user information, enabling the context agent to query the vector space for the specific information it needs on the current topic. However, implementing this approach might be complex in practice, as it could make it challenging to overwrite knowledge, such as updating “student does not know pointers” to “student knows pointers.”
A more systematic solution, like a syllabus with topics and confidence scores in a traditional database, could ensure topic mastery, but it can be difficult to get a LLM to reliably generate the necessary commands for reading and writing to the database. Utilizing reinforcement learning to enhance the LLM’s capability to generate accurate commands is a promising approach; however, it falls beyond the scope of my current resources.
I’m open to any other ideas on handling user context.
Supplementary Thoughts
Bloom identified a combination of 4 variables that could potentially produce a 2 sigma effect:
- Learner
- Instructional material
- Teacher
- Home environment or peer group
AI Tutors have the potential to address the 2nd and 3rd variables, while the 1st is likely a matter of individual agency. But what about the fourth? Reflecting on the last variable and considering how it might be addressed can be a valuable exercise. I have found Twitter to be an invaluable tool for cultivating a peer group through a carefully curated following list. This allows me, for example, to connect with the driven community of Silicon Valley even from thousands of miles away.